

Companies cannot afford to pay for glitchy, underperforming communication systems and implementation delays that bring direct, immediate costs in wasted time, lower productivity, and customer churn.
At the same time, contact center leaders are aware that providing a continuously positive experience across multiple communications channels will be critical to attracting new customers and building loyalty.
Many contact center leaders are looking to stem customer churn and reduce cost to serve – while also innovating and improving the customer journey – by introducing and installing new technologies and/or moving to the cloud to access them. But how can they be sure that technology improvement projects deliver the anticipated ROI?
There are many steps in the lifecycle of a customer interaction or customer journey where service inefficiencies creep in and the user experience is compromised. When these failures are repeated at scale, the costs can be high. Some of the most common – and costly – technology failures are listed here.
1. Project delays
Overruns in projects to refresh contact center technology, introduce new services, or build new contact centers can quickly grow into vast cost increases. The same is true of contact center cloud migrations.
Independent research commissioned by Hammer revealed that 73% of contact center leaders redesign their contact center when they migrate to the cloud, but just over a third actually achieve the goals they set for their migration.
Issues that are not handled in the pre-production stage have a direct negative impact – devastating customer satisfaction levels and your company’s reputation – while encouraging customers to take their business to your competitors. No one wants their customers to be guinea pigs for new technology systems, but it happens all too often.

2. Necessary rollbacks
Horrifying as it may sound, we encounter necessary rollbacks on a fairly frequent basis. We know of several cases where a contact center was planning to change vendors but had to roll back at the point they were about to go live, because the technology just wasn’t working.
These cases have huge monetary ramifications, as massive investments of time and resources (both human and technology) are made, not to mention the disruption to daily operations. The only safe way to de-risk situations such as these is to carry out rigorous testing beforehand.
3. Dropped calls
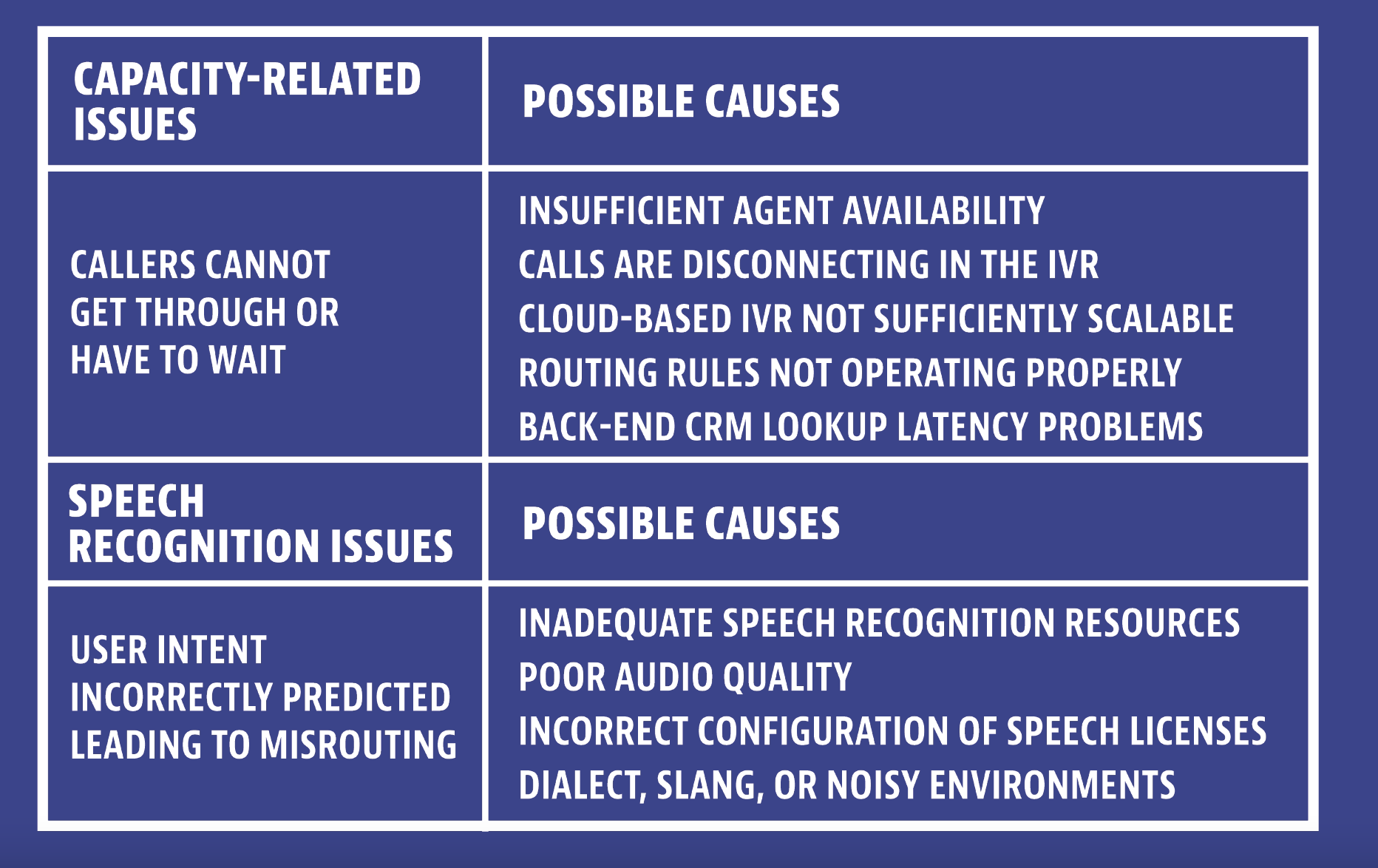
Busy lines or dropped calls are a major cause of customer frustration. Most people overlook the fact that contact center queues are not always caused by shortages of agents to take them. They are just as likely to result from lack of capacity at the carrier network side.
Even worse from a quality assurance point of view, dropped calls can easily – and frequently do – go unnoticed by call center operations teams. Until agents start taking angry calls from customers, that is, by which time the customer experience (CX) is already compromised.
But how can [contact centers] be sure that technology improvement projects deliver the anticipated ROI?
If you’ve moved to the cloud, you may believe you have sidestepped this issue, but can you be sure? In our experience, contact center-as-a-service (CCaaS) providers have been known to fail unanticipated load tests. It probably happens more frequently than you imagine.
Once the issue is reported, contact center leaders face the question “Was it a random event? Or is it an urgent priority to fix?” The root cause may be complex and well-hidden. Here are some scenarios you might recognize:

Determining who is responsible for the failure presents a further challenge. There may be parts of your infrastructure where assurance falls to a third-party host. But as mentioned earlier, technology partners are not infallible. How much visibility do you have?
Issues can also go unnoticed because of the way operations and organizational priorities are structured.
For example, session border controllers (SBCs), which are not usually on the radar screens of business leaders, are managed by IT: which may not notice any negative impact to call quality as they monitor enterprise bandwidth from network operating centers (NOCs).
Independent validation of your CCaaS provider
Migrating to the cloud has delivered improved scalability and flexibility to contact center operations and reduced the need to invest in expensive infrastructure with the associated risk of redundancy.
But how do you verify claims about uptime reliability made by your CCaaS provider? The truth is you must take their word for it.
One of the benefits promised by moving to the cloud is elasticity. But have you ever paused to think about what happens when every multi-tenancy client needs their CCaaS vendor capacity at the same time?
If you were to spring an unexpected load test on your CCaaS provider, would they pass or fail? The answer is that without independent end-to-end testing, you just can’t know.
4. Inefficient call routing
Organizations today have the option of using data-driven personalization strategies, skills-based routing, and even artificial intelligence (AI)-enabled proactive knowledge management to equip agents with the information they need to handle a broader range of inquiries.
Everybody wants to avoid callers being transferred multiple times before their inquiries are resolved. Yet poor routing continues to be a bugbear for customers and agents alike.
Sophisticated routing strategies depend upon multiple components working together to achieve success, which of course means multiple points of failure.
Issues
- Does each routing rule event happen as intended?
- How do you verify the right data gets screen-popped onto the agent desktop?
- Does the data appear fast enough to allow the agent to personalize the customer conversation?
Some Possible Causes
- CRM data look-up suffers latency.
- Routing rules are misconfigured.
- CTI data is not being passed by the SBC or collected by the IVR/interactive voice agent (IVA).
- Failure to deliver customer data embedded in a chat session.
5. IVR failures
Poor routing outcomes are often linked to poor IVR performance. For if designed well, IVR can orchestrate successful customer journeys and use internal resources more efficiently. But if not, it is a source of service dysfunction prompting users to seek better experiences elsewhere.
Sophisticated routing strategies depend upon multiple components working together to achieve success…
Problems here are commonplace, manifest, and costly too. They infuriate customers, leading to longer call times, fewer positive outcomes, and agent attrition.
- How often are customers getting trapped in IVR loops because of a phone keypad that stops working?
- Or misconfigured messages offering incorrect information?
- How many negative experiences occur before you notice customers are not getting through in an IVR outage?
Here are some further scenarios where testing will surface, pinpoint and quantify challenges:
As customer journeys become more complex, the IVR is frequently updated; three-quarters of contact center leaders say the IVR gets updated as often as the business needs or wants. (Hammer, State of Contact Center Testing Report)
Systems like IVRs are updated regularly, meaning problems with the customer journey often won’t come to light until after updates are released into the live environment.
6. Poor voice quality
Hybrid-working is now a permanent feature of many contact center operations. Yet do you know if voice quality and data access are consistent across all your agents: whether they are working-from-home (WFH) or in the contact center?
Poor voice quality can slow down communication and extend the length of the call, negatively impacting the quality of the interaction for both the customer and the agent. Inadequate network reliability and speed can also impact agent desktop screen pops.
7. Reduced application performance
Reduced application performance is another technology failure that can significantly impact productivity in the contact center environment.
Agent login success, CTI and screen-pop look-ups, customer data updates, and post-call surveying all depend upon back-end applications performing optimally. Improper data presentation and slow data arrival are both major drains on productivity (see our Cost of Technology Failure calculation diagram in Figure 1).

Establishing Responsibility
Finding solutions to these technology failures lies in uncovering them through automated testing. For example, by coupling it with monitoring you can understand how the agent and customer experience varies between contact center and WFH agents. Maybe WFH advisors are experiencing poor voice quality, how can you know what needs to be done to optimize consistency?
Without automated testing, then there is no alternative but to take shortcuts. But at what cost? Independent research commissioned by The Customer Experience Foundation shows that poor or no testing increases delay and costs in 79% of all projects.
The reality is fully comprehensive manual testing in today’s fast-paced contact center environment prior to deployment is rarely possible, especially given the pressure reported on dev ops resources.
The answer is that successful journeys require cooperation between all your technology partners.
Automated testing can not only verify that customer interaction and agent experiences perform as the organization intended, but that they will continue to do so up to peak capacity and beyond. And do so in a fraction of the time and at a fraction of the cost required for manual testing: if it were carried out to the same level of detail and complexity.
The question lies with which party should perform the automated testing? Even today, many contact center leaders believe that testing should be the responsibility of the technology vendor or cloud provider.
But the problem is that today’s contact center platforms are very complex, with interdependencies and integrations between components, as well as mixed vendor environments comprising both on-premise and cloud-hosted solutions.
It can be difficult to allocate responsibility when multiple systems are working together. Take the example of a cloud provider IVR that links to a third-party CRM system. If the CRM data look-up is slow, whose responsibility is that? Typically testing is required to pinpoint the cause of the latency, as well as cooperation between both technology vendors.
In this environment, not only are there multiple points of failure, but it can often be difficult to determine whose responsibility it is to resolve the issue. When problems lie in the interaction between different vendors’ products, it’s hard for any one vendor to pinpoint the problem’s source.
The question every contact center leader should be asking themselves is “Who owns the customer journey?” Do you really want to leave it in the hands of your cloud provider, or your CRM vendor, or even your network provider, or carrier?
The answer is that successful journeys require cooperation between all your technology partners. They require end-to-end test plans to pre-empt the risks that typically affect CX and increase operational costs. And they depend upon rapid identification of problems and a willingness to collaborate to fix issues.
It is vital to test not just individual, siloed components, but the complex multi-vendor, multi-application, multi-channel environment as a whole. And this requires the business – not the technology vendor – to take full ownership of the customer journey.




